
Table of Contents
Could you explain the storage classes in C?
Candidate: Certainly! In C, storage classes determine the scope, lifetime, and visibility of variables and functions. There are four primary storage classes: auto, register, static, and extern.
- auto: Variables declared within a block (function or compound statement) without any storage class specifier default to auto. They are automatically allocated memory when the block is entered and deallocated when the block is exited. Their scope is limited to the block in which they are defined.
- register: The register storage class is used to suggest the compiler to store the variable in a register for faster access. However, the compiler may ignore this suggestion. Variables declared with the register storage class have the same lifetime and scope as auto variables.
- static: Variables and functions declared with the static storage class have a lifetime that extends throughout the program’s execution. When used with local variables, it retains the value between function calls. When used with global variables, it restricts the visibility of the variable to the file in which it is declared.
- extern: The extern storage class is used to declare variables and functions that are defined in other files. It extends the visibility of the variable or function to other files.

#include <stdio.h>
// Global variable with static storage class
static int globalStaticVar = 10;
// Global variable with extern storage class (declared in another file)
extern int globalExternVar;
int main() {
// Local variable with auto storage class
auto int localVarAuto = 20;
// Local variable with register storage class
register int localVarRegister = 30;
// Static local variable
static int localVarStatic = 40;
printf("Local variable (auto): %d\n", localVarAuto);
printf("Local variable (register): %d\n", localVarRegister);
printf("Local variable (static): %d\n", localVarStatic);
printf("Global variable (static): %d\n", globalStaticVar);
printf("Global variable (extern): %d\n", globalExternVar);
return 0;
}
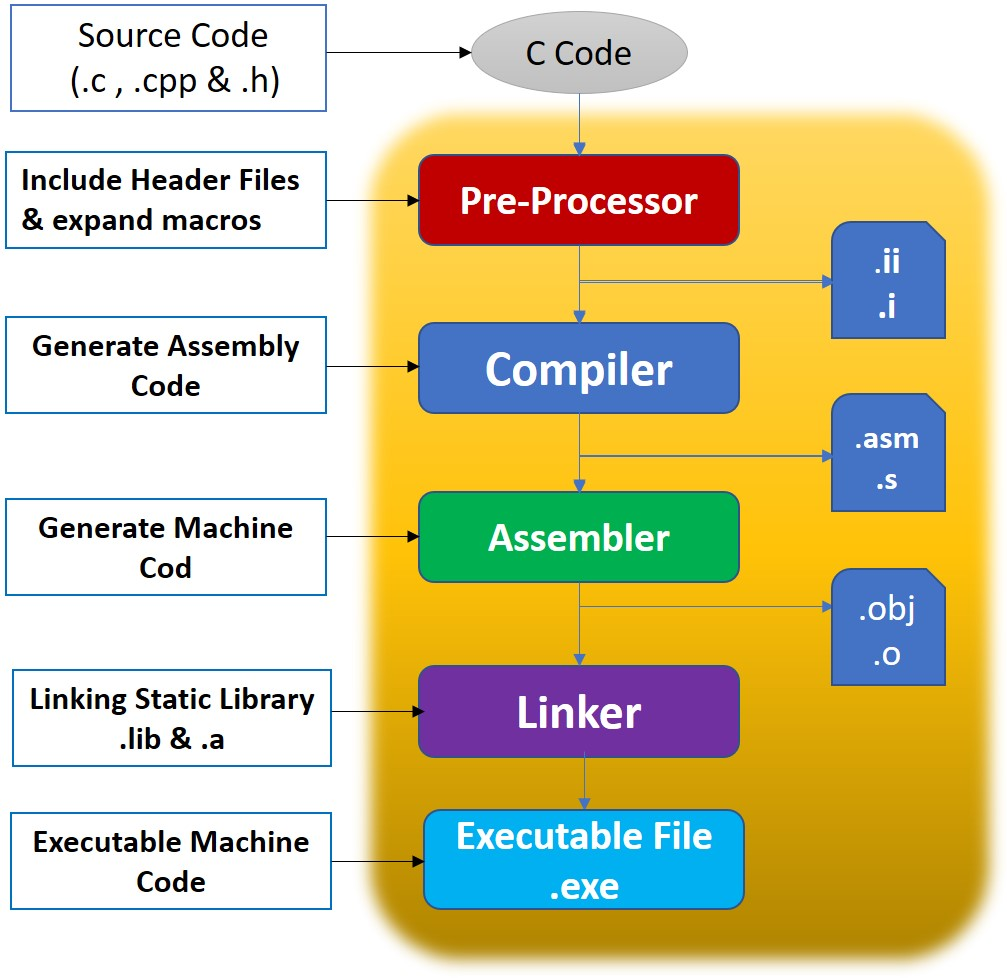
Could you explain the compilation stages in C?
- Preprocessing: In this stage, the preprocessor performs text substitution and macro expansion based on directives such as #include, #define, and #ifdef. It also removes comments and whitespace. The output of this stage is called a preprocessed source file.
- Compilation: The preprocessed source file is passed to the compiler, which translates it into assembly language or intermediate code specific to the target platform. This stage involves lexical analysis, syntax analysis, semantic analysis, and code generation.
- Assembly: The assembly stage converts the intermediate representation generated by the compiler into machine code or object code. It produces one or more object files containing machine instructions.
- Linking: In the linking stage, the linker combines multiple object files along with any necessary library files to produce a single executable file. It resolves external references, such as function calls and variable accesses, across different modules and libraries.
- Loading (optional): In some cases, particularly in systems with dynamic linking or loading, an additional loading stage may occur. During this stage, the operating system loads the executable file into memory and prepares it for execution.
Explain about Structure padding and its advantage with example code
Structure padding refers to the addition of unused bytes between structure members to align them properly in memory. It’s primarily done to improve memory access efficiency, as most CPUs require data to be aligned to certain memory addresses for optimal performance.
Here’s an example demonstrating structure padding and its advantages:
#include <stdio.h>
// Define a structure without padding
struct WithoutPadding {
char a; // 1 byte
int b; // 4 bytes (on a typical 32-bit system)
char c; // 1 byte
};
// Define a structure with padding
struct WithPadding {
char a; // 1 byte
char pad1[3]; // Padding to align 'b' to 4-byte boundary
int b; // 4 bytes
char c; // 1 byte
};
int main() {
printf("Size of struct WithoutPadding: %zu bytes\n", sizeof(struct WithoutPadding));
printf("Size of struct WithPadding: %zu bytes\n", sizeof(struct WithPadding));
return 0;
}
In this example, the structure WithoutPadding has three members: a, b, and c. However, because int typically requires alignment on a 4-byte boundary, the compiler adds 3 bytes of padding after a to align b properly. As a result, the total size of WithoutPadding is 8 bytes (1 + 4 + 1 + 2 padding).
On the other hand, the structure WithPadding includes an explicit array pad1 to ensure proper alignment of b. This eliminates the need for the compiler to add padding, resulting in a more efficient memory layout. The total size of WithPadding is also 8 bytes (1 + 3 padding + 4 + 1), but the padding is managed explicitly.
Advantages of structure padding:
- Improved memory access: Properly aligned data can be accessed more efficiently by the CPU, resulting in faster execution.
- Optimized cache usage: Padding can help avoid cache line splitting, improving cache utilization and reducing memory access latency.
- Compatibility with hardware: Some hardware architectures require specific data alignment for optimal performance, and structure padding helps achieve this alignment.
What are the compilation stages in c
In C, the compilation process involves several stages, each responsible for translating the source code into executable machine code. These stages typically include:
Preprocessing: In this stage, the preprocessor directives are processed. Directives such as #include, #define, and #ifdef are handled, and header files are included in the source code. Macros are also expanded during this stage.
Compilation: The preprocessed source code is translated into assembly language or an intermediate representation known as object code. This stage involves lexical analysis, syntax analysis, semantic analysis, and code generation.
Assembly: If the compiler generates assembly code in the previous stage, this code is assembled into machine language instructions by the assembler. Each assembly language instruction corresponds to one or more machine instructions.
Linking: The object code generated from multiple source files is combined and linked together to produce the final executable file. This stage resolves external references, such as function calls and global variables, by locating the corresponding definitions in other object files or libraries and creating a unified executable.

What is the difference between Actual Parameters and Formal Parameters? For example code
- Actual Parameters: Also known as arguments, actual parameters are the values or expressions passed to a function or procedure when it is called. These are the values that the function operates on. Actual parameters are provided by the caller of the function and can be variables, constants, or expressions.
- Formal Parameters: Also known as parameters or formal arguments, formal parameters are the variables listed in the function definition. They act as placeholders for the values to be supplied by the caller (actual parameters). The function uses these parameters to perform its task. Formal parameters are defined by the function or procedure and specify the type and number of values it expects to receive.
Here’s a simple example in C to illustrate the difference between actual parameters and formal parameters:
#include <stdio.h>
// Function declaration with formal parameters
void add(int a, int b);
int main() {
int x = 5, y = 3;
// Calling the function with actual parameters
add(x, y);
return 0;
}
// Function definition with formal parameters
void add(int a, int b) {
int sum = a + b;
printf("The sum of %d and %d is %d\n", a, b, sum);
}
In this example:
- add is a function with two formal parameters a and b.
- In main, x and y are actual parameters passed to the add function.
- Inside the add function, a and b act as placeholders for the actual parameters x and y.
What is the difference between structure and union?
In C programming, both structures and unions are used to group different types of data under a single name. However, they have some key differences:
Memory Allocation:
- Structure: Each member of a structure is allocated its own memory space. The total memory occupied by a structure is the sum of memory occupied by each member.
- Union: In contrast, a union allocates memory such that all members share the same memory space. The memory allocated for a union is large enough to accommodate its largest member.
Accessing Members:
- Structure: You can access each member of a structure independently using its name along with the dot (.) operator.
- Union: Since all members of a union share the same memory space, changing the value of one member affects the values of all other members. You can only access one member at a time.
Memory Utilization:
- Structure: Structures are useful when you need to store multiple pieces of related information, each with its own separate memory space.
- Union: Unions are useful when you need to store different types of data in the same memory location, but only one at a time. They are often used to save memory when you know that only one member will be used at any given time.
Here’s a simple example to illustrate the difference:
#include <stdio.h>
// Structure definition
struct Person {
char name[20];
int age;
};
// Union definition
union Data {
int num;
float fnum;
};
int main() {
// Structure variable
struct Person person1;
person1.age = 30;
// Union variable
union Data data;
data.num = 10;
printf("Value of num: %d\n", data.num);
data.fnum = 3.14;
printf("Value of fnum: %.2f\n", data.fnum);
return 0;
}
In this example:
- struct Person defines a structure with two members: name and age.
- union Data defines a union with two members: num and fnum.
- Memory for person1 is allocated separately for name and age.
- Memory for data is shared between num and fnum. Changing the value of one member (num) affects the value of the other member (fnum).
What is Structure Padding for 32bit?
In a 32-bit system, the default alignment for most data types is usually their size. Here’s a brief overview of structure padding in a 32-bit system:
- Data Alignment: In a 32-bit system, most data types are aligned to their size. For example, an int typically occupies 4 bytes and is aligned on a 4-byte boundary.
- Padding: If the members of a structure are not naturally aligned, the compiler may insert additional bytes (padding) between the members to ensure proper alignment. This padding ensures that each member starts at an appropriate memory offset.
- Size of the Structure: The size of a structure may be larger than the sum of the sizes of its members due to padding. The actual size of a structure is determined by the alignment requirements of its members.
Here’s a simple example to illustrate structure padding in a 32-bit system:
#include <stdio.h>
// Define a structure with different data types
struct Example {
char c; // 1 byte
int i; // 4 bytes
double d; // 8 bytes
};
int main() {
// Print the size of the structure
printf("Size of struct Example: %lu bytes\n", sizeof(struct Example));
return 0;
}
In this example:
- The structure Example contains a char, an int, and a double.
- The size of char is 1 byte, int is 4 bytes, and double is 8 bytes.
- However, due to structure padding, the actual size of Example may be larger than the sum of these sizes. On a 32-bit system, the size of Example might be 16 bytes due to padding to align the int and double members on 4-byte and 8-byte boundaries, respectively.
What is DMA?
DMA stands for Direct Memory Access. It’s a feature found in many microcontrollers and computer systems that allows peripherals (such as UART, SPI, ADC, etc.) to transfer data to and from memory without involving the CPU. DMA controllers are hardware modules that manage these data transfers independently of the CPU.
In embedded C, DMA is commonly used to offload data transfer tasks from the CPU, freeing up CPU resources for other tasks. It’s especially useful for handling high-speed data transfers, such as streaming data from sensors, audio, or video sources.
DMA operations typically involve the following steps:
- Initialization: Configure the DMA controller, including setting the source and destination addresses, transfer size, and transfer mode (e.g., single or block transfer).
- Start Transfer: Trigger the DMA transfer, usually by writing to specific control registers in the DMA controller.
- Data Transfer: The DMA controller transfers data between the peripheral and memory without CPU intervention. It can perform transfers in various modes, such as memory-to-memory, memory-to-peripheral, or peripheral-to-memory.
- Completion: Once the transfer is complete, the DMA controller may generate an interrupt or signal to notify the CPU.
- DMA offers several advantages in embedded systems:
- Efficiency: By offloading data transfer tasks from the CPU, DMA allows the CPU to focus on other processing tasks, improving overall system performance and efficiency.
- Speed: DMA transfers data directly between peripherals and memory, often faster than CPU-managed transfers.
- Reduced Overhead: Since the CPU is not directly involved in data transfers, there’s less overhead associated with managing data movement, leading to lower power consumption and better system responsiveness.
- Scalability: DMA controllers can often handle multiple channels and priorities, allowing for complex data transfer scenarios and support for various peripherals.
In embedded C programming, developers typically interact with DMA controllers through peripheral-specific registers and configuration settings provided by the microcontroller’s manufacturer. Configuration involves setting up DMA channels, specifying transfer parameters, and handling DMA-related interrupts or events.
Can you explain what a dangling pointer is in C
Candidate: Certainly. In C programming, a dangling pointer refers to a pointer that points to a memory location that has been deallocated or freed. When the memory associated with a pointer is deallocated using the free() function, but the pointer is not set to NULL, it becomes a dangling pointer. Attempting to dereference a dangling pointer can lead to undefined behavior, as it may point to a memory location that has been reused for other purposes or no longer exists.
Interviewer: Why is it important to handle dangling pointers properly?
Candidate: Handling dangling pointers properly is crucial because attempting to dereference a dangling pointer can lead to unexpected behavior and difficult-to-debug issues in the code. By setting dangling pointers to NULL after freeing the associated memory, we can prevent accidental dereferencing and make it easier to detect and diagnose memory-related errors during runtime.
Interviewer: Can you provide an example of how to handle a dangling pointer?
Here’s an example of a dangling pointer in C:
#include <stdio.h>
#include <stdlib.h>
int main() {
int *ptr = (int *)malloc(sizeof(int)); // Allocate memory
*ptr = 42; // Assign a value to the allocated memory
free(ptr); // Free the allocated memory
// Now 'ptr' is a dangling pointer
// Attempt to dereference the dangling pointer
printf("Value at dangling pointer: %d\n", *ptr); // This can lead to undefined behavior
return 0;
}
Here’s an example of how to handle a dangling pointer properly by setting it to NULL after freeing the associated memory
#include <stdio.h>
#include <stdlib.h>
int main() {
// Allocate memory and assign it to a pointer
int *ptr = (int *)malloc(sizeof(int));
// Check if memory allocation was successful
if (ptr != NULL) {
// Use the allocated memory
// Free the allocated memory
free(ptr);
// Set the pointer to NULL to avoid dangling pointer
ptr = NULL;
}
return 0;
}
Can you explain the difference between a macro and an inline function in C, and provide example code for each
Candidate: Certainly. Both macros and inline functions are mechanisms used in C to improve code efficiency, but they operate differently and have different use cases.
A macro is a preprocessor directive that performs text substitution. When the code is compiled, the macro is replaced with its corresponding code wherever it is used in the program. Macros are typically defined using the #define directive and can take arguments. One common use case for macros is to define constants or perform simple operations that don’t require type checking.
On the other hand, an inline function is a function defined with the inline keyword, which suggests to the compiler that the function’s code should be inserted directly into the calling code instead of being called as a separate function. Inline functions are more flexible and type-safe compared to macros because they behave like regular functions and are subject to the same scoping and type rules. They also support type checking and can be used to define more complex operations.
Here’s an example of a macro and an inline function to demonstrate the difference:
What is the difference between int and unsigned int?
| Aspect | int | unsigned int |
| Data Range | Typically -2,147,483,648 to 2,147,483,647 (depending on the platform) | Typically 0 to 4,294,967,295 (depends on the platform) |
| Memory Consumption | Usually 4 bytes (32 bits) | Typically 0 to 4,294,967,295 (depending on the platform) |
| Sign | Can represent both positive and negative numbers | Represents only non-negative numbers (zero and positive integers) |
| Overflow | Can overflow in both positive and negative directions | Overflow results in wraparound behavior, reaching 0 if positive overflow, or UINT_MAX if negative overflow |
How does a switch statement differ from an if-else statement?
| Feature | Switch Statement | If-Else Statement |
|---|---|---|
| Syntax | Uses switch keyword followed by a single expression | Uses if, else if, and else keywords |
| Usage | Best for multiple possible values of a single expression | More versatile, handles a wider range of conditions |
| Evaluation | Expression evaluated once jumps to matching case | Conditions are evaluated sequentially until true |
| Fall-through | Can have fall-through behavior if no break is used | No implicit fall-through behaviour |
| Expression Types | Limited to integral types or enumerated types | Can evaluate any boolean expression |
| Execution Efficiency | Efficient when multiple cases match the same expression | Less efficient for complex boolean expressions |
| Readability | Clearer and more concise for simple value-based decisions | Better for complex conditions with multiple checks |